True Multimodal In-Context Learning Needs Attention to the Visual Context

Multimodal Large Language Models (MLLMs), built on powerful language backbones, have enabled Multimodal In-Context Learning (MICL)—adapting to new tasks from a few multimodal demonstrations consisting of images, questions, and answers. Despite showing noticeable improvement on standard vision-language datasets, current MLLMs struggle to leverage visual information in the demonstrations. Specifically, they tend to neglect visual cues and over-rely on textual patterns, leading to mere text imitation rather than genuine multimodal adaptation. This behavior makes MICL still unimodal and largely restricts its practical utility.
Multimodal In-Context Learning (MICL) enables models to adapt to new tasks from few multimodal demonstrations. However, current MLLMs struggle to effectively utilize visual information in demonstrations, tending to overlook visual cues and over-rely on textual patterns. This results in textual pattern imitation rather than genuine multimodal adaptation. 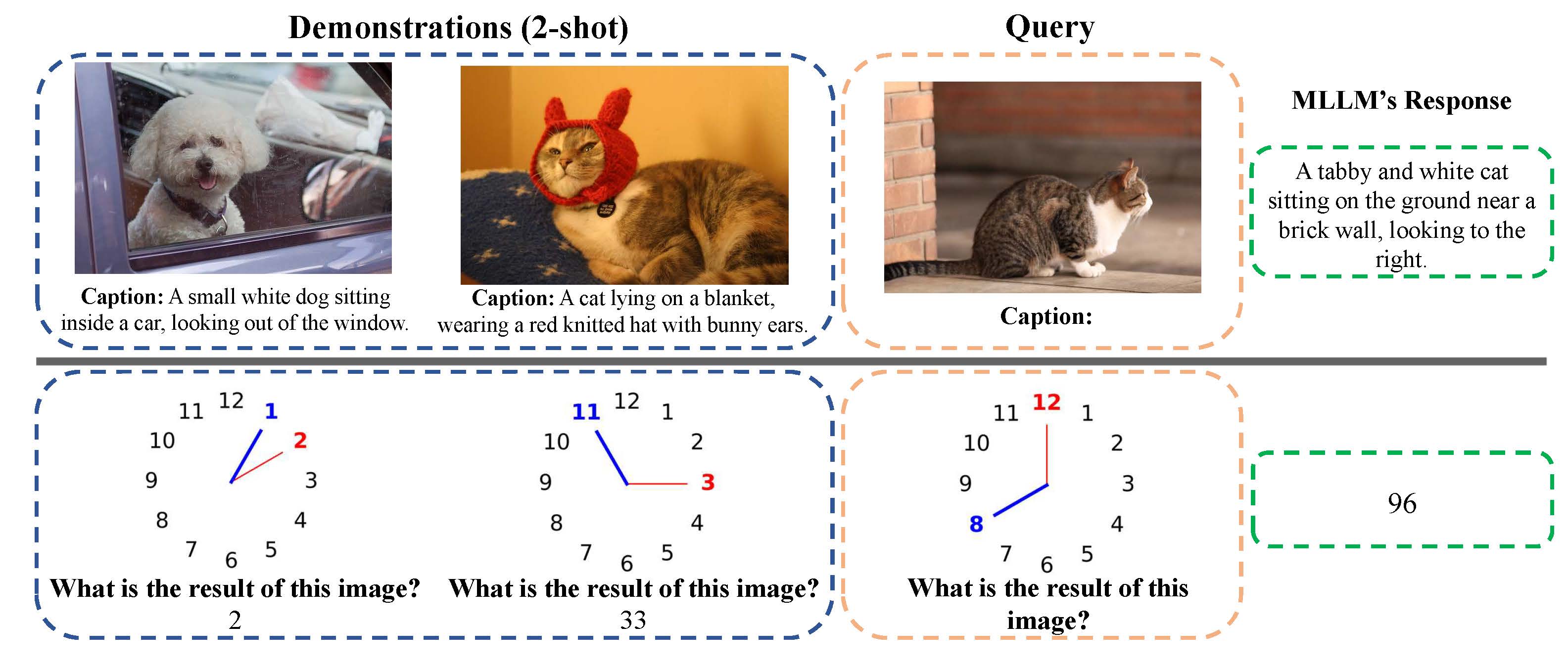
This limitation is often concealed by improved performance on tasks that do not require deep visual context understanding. For example, models can generate reasonable captions for query images even without referencing demo images, as they rely on textual pattern following rather than multimodal understanding.
To address the visual context neglect in MICL, we introduce Dynamic Attention Reallocation (DARA), an efficient fine-tuning strategy that encourages models to attend to visual context by rebalancing attention across visual and textual tokens. DARA introduces a set of learnable attention-balancing parameters that dynamically regulate the influence of visual and textual tokens during attention computation.
DARA is remarkably lightweight, introducing only a small number of learnable parameters for rapid adaptation. We insert DARA into the first transformer layer of the language backbone, specifically targeting attention score matrices in all attention heads. Given 5 images (4-shot demos + query) and 32 attention heads, the total number of learnable parameters is only 5×32=160. With around 100 parameters, DARA achieves up to 10% improvement on downstream tasks.
To better understand how DARA affects attention, we present both qualitative and quantitative visualizations showing DARA's impact on attention patterns.
The spatial attention heatmap shows that without DARA, both demonstration and query images receive minimal attention, as indicated by predominantly blue regions. After applying DARA, attention over image tokens increases markedly (more red/yellow areas), indicating enhanced attention to visual input and improved visual grounding. 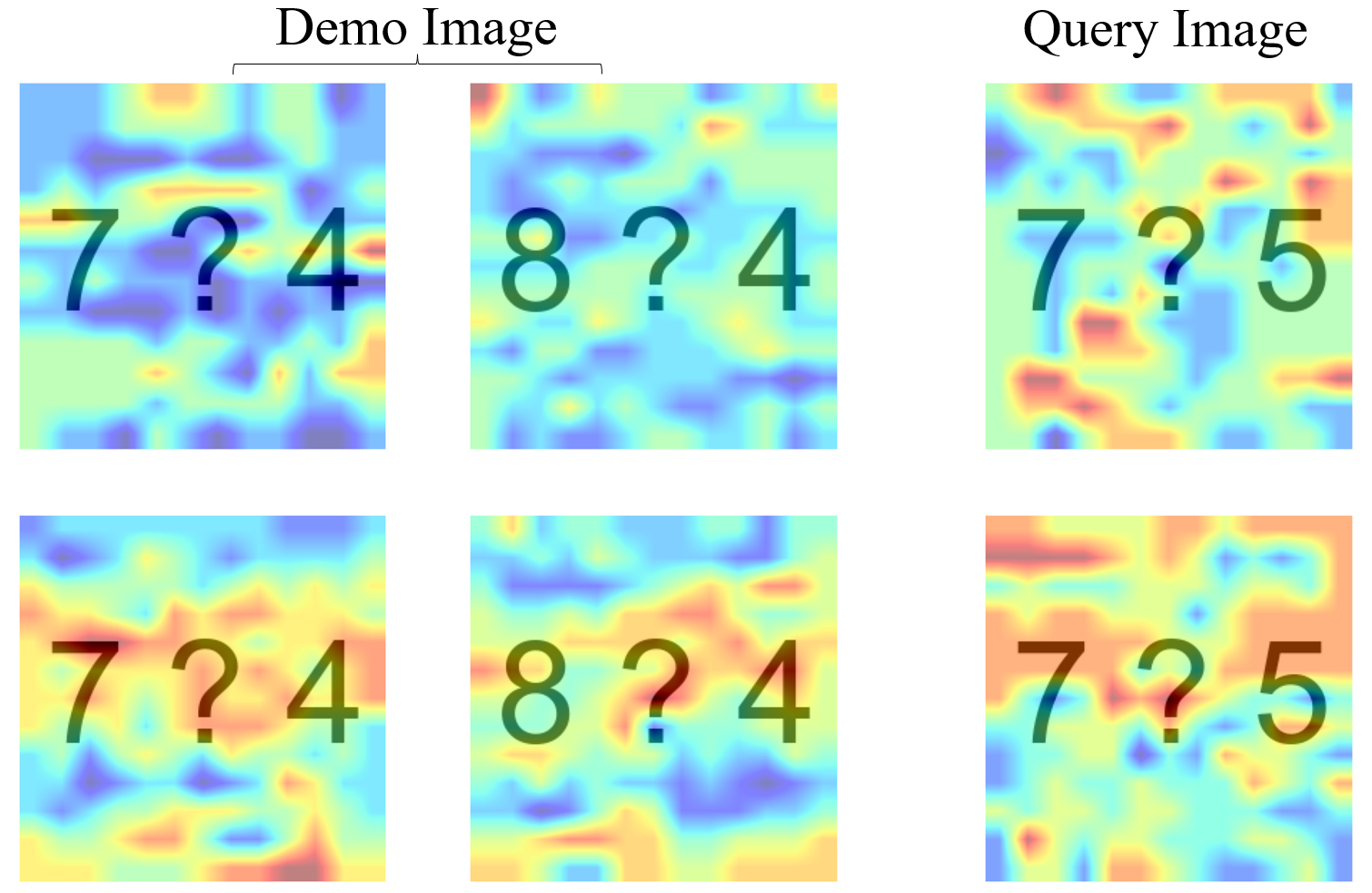
We quantitatively compare attention allocation across different modality tokens. Without DARA, the model allocates only 28% of attention to image tokens, focusing primarily on text. With DARA, this increases to 46.7%, demonstrating a substantial shift toward visual content during response generation. 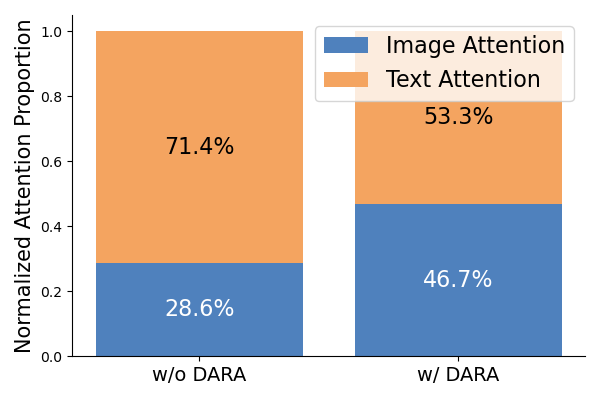
The learned attention amplification factors across different attention heads and images reveal structured visual emphasis. DARA induces clear redistribution: demo images consistently receive factors larger than 1, encouraging stronger reliance on context, while different heads specialize in different aspects - for example, Head 1 emphasizes Demo 2 (1.27), while Head 5 emphasizes Demo 4 (1.32). 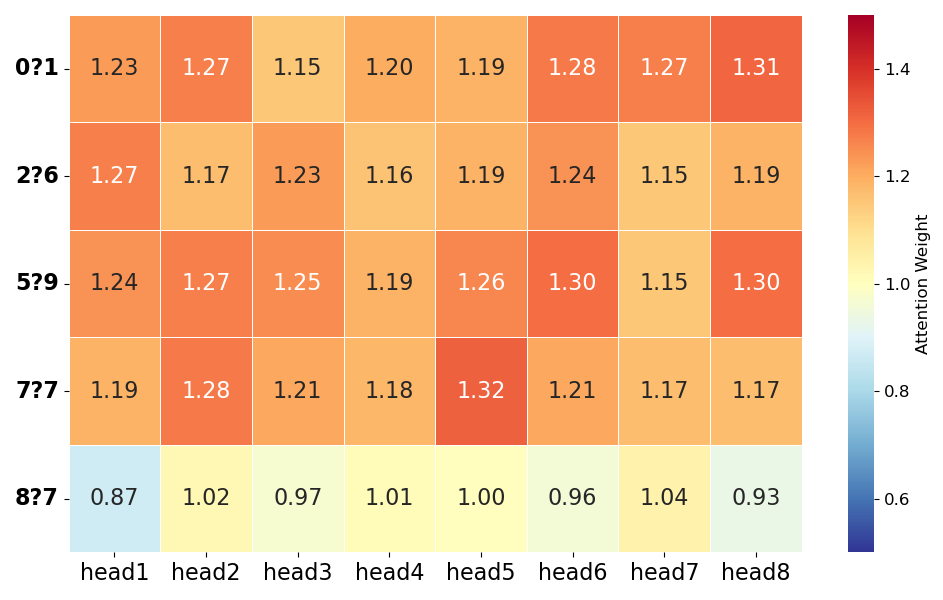
We introduce TrueMICL, a MICL-dedicated dataset designed with a critical principle: correct responses must rely on comprehensive understanding of multimodal context, especially visual information. Unlike existing MICL datasets that focus on task recognition, TrueMICL emphasizes task learning where models must understand relationships between visual and textual elements.
To this end, we have designed a novel MICL-dedicated dataset, TrueMICL, guided by the following principles:
TrueMICL comprises 867 samples across 4 task types and 7 distinct tasks, covering mathematical reasoning, pattern finding, and novel visual concept learning. The dataset is designed to be scalable and configurable for different levels of difficulty.
The table below shows representative examples from TrueMICL, illustrating how each task requires understanding the relationship between images and text in demonstrations to correctly answer queries.
| Category | Task | Demo 1 | Demo 2 | Query | Label | Explanation | ||
|---|---|---|---|---|---|---|---|---|
| Math Reasoning | Operator Induction |  | 0 |  | 12 |  | 8 | Multiplying the two numbers in the image |
| Clock Math | 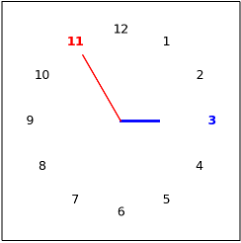 | 14 | 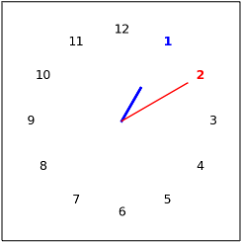 | 3 | 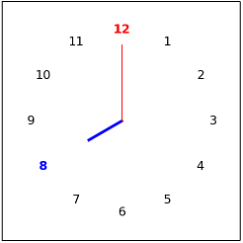 | 20 | Adding the two numbers in the clock | |
| Concept Binding | Outlier Detection |  | Green | 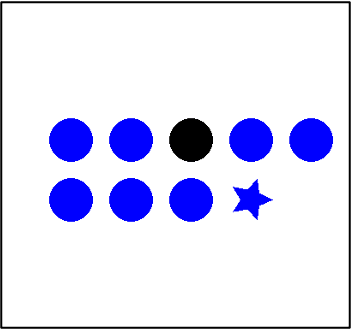 | Black | 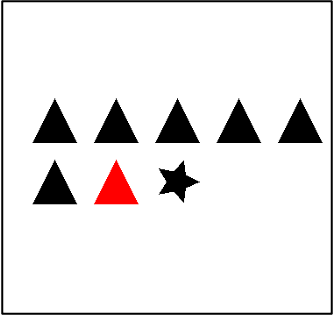 | Red | The outlier color in the image |
| CLEVR Count |  | 2 |  | 5 |  | 2 | The number of spheres | |
| Pattern Finding | Sudoku | 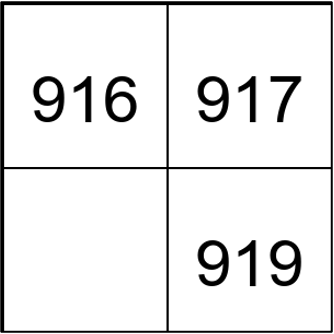 | 918 | 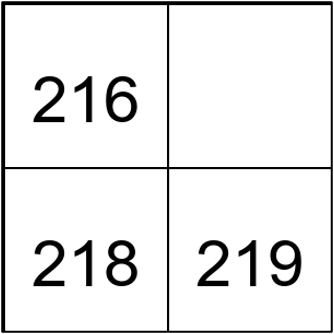 | 217 | 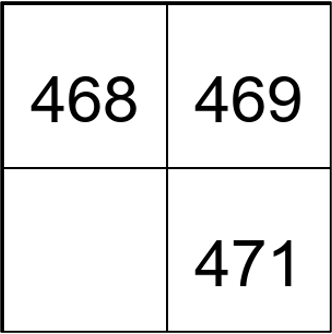 | 470 | The missing number in between |
| Palindrome |  | 7 |  | 9 |  | 9 | To form palindrome number | |
| Novel Concept | Character Classification |  | Flora |  | Walter |  | Flora | The same character in the demo |
Table: An overview of task examples in TrueMICL. The label to the query requires the model to learn the relationship between images and text in the demonstrations.
Our comprehensive experiments across various MLLMs demonstrate the effectiveness of both DARA and TrueMICL. Current MLLMs find TrueMICL evaluation tasks quite challenging, and DARA significantly improves MICL performance on both our evaluation tasks and standard VL tasks. 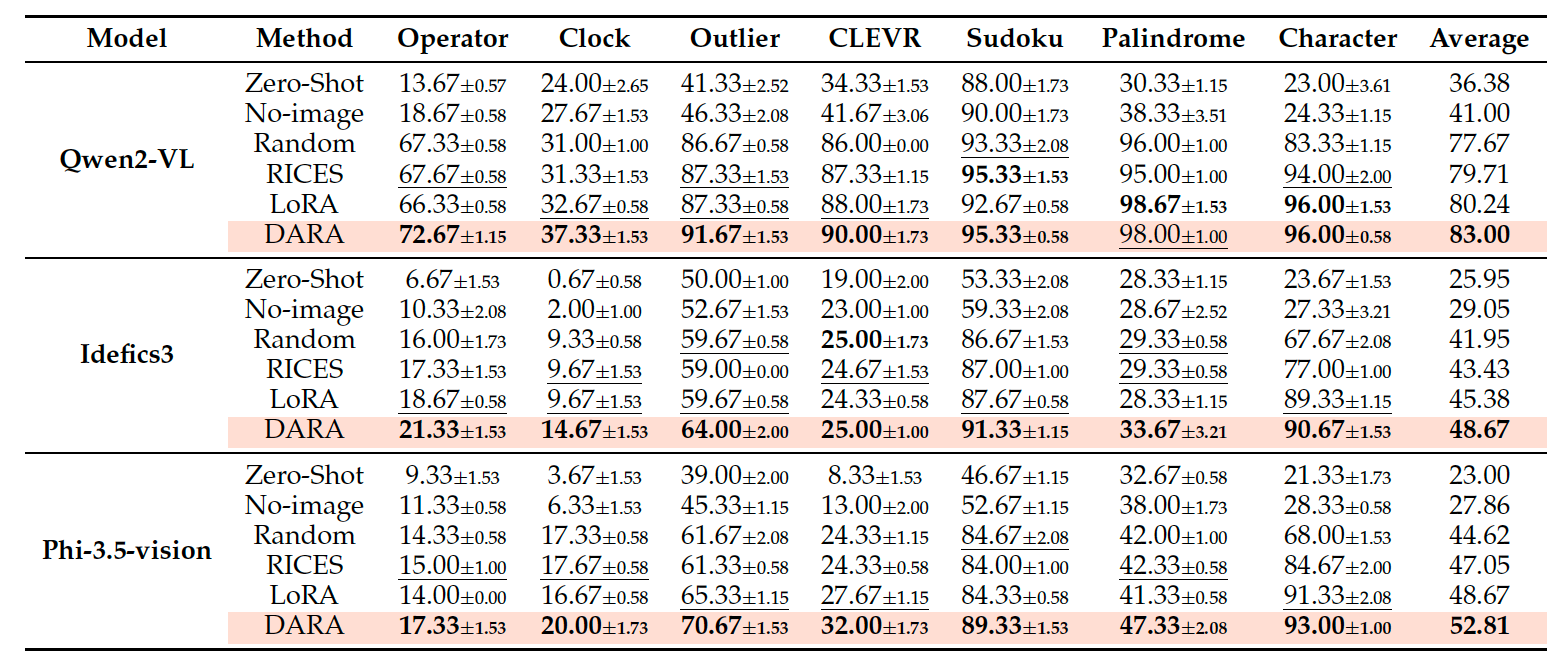
@article{chen2025true,
title={True Multimodal In-Context Learning Needs Attention to the Visual Context},
author={Chen, Shuo and Liu, Jianzhe and Han, Zhen and Xia, Yan and Cremers, Daniel and Torr, Philip and Tresp, Volker and Gu, Jindong},
journal={arXiv preprint arXiv:2507.15807},
year={2025}
}
This template is adapted from Eyes Wide Shut.