
Abstract
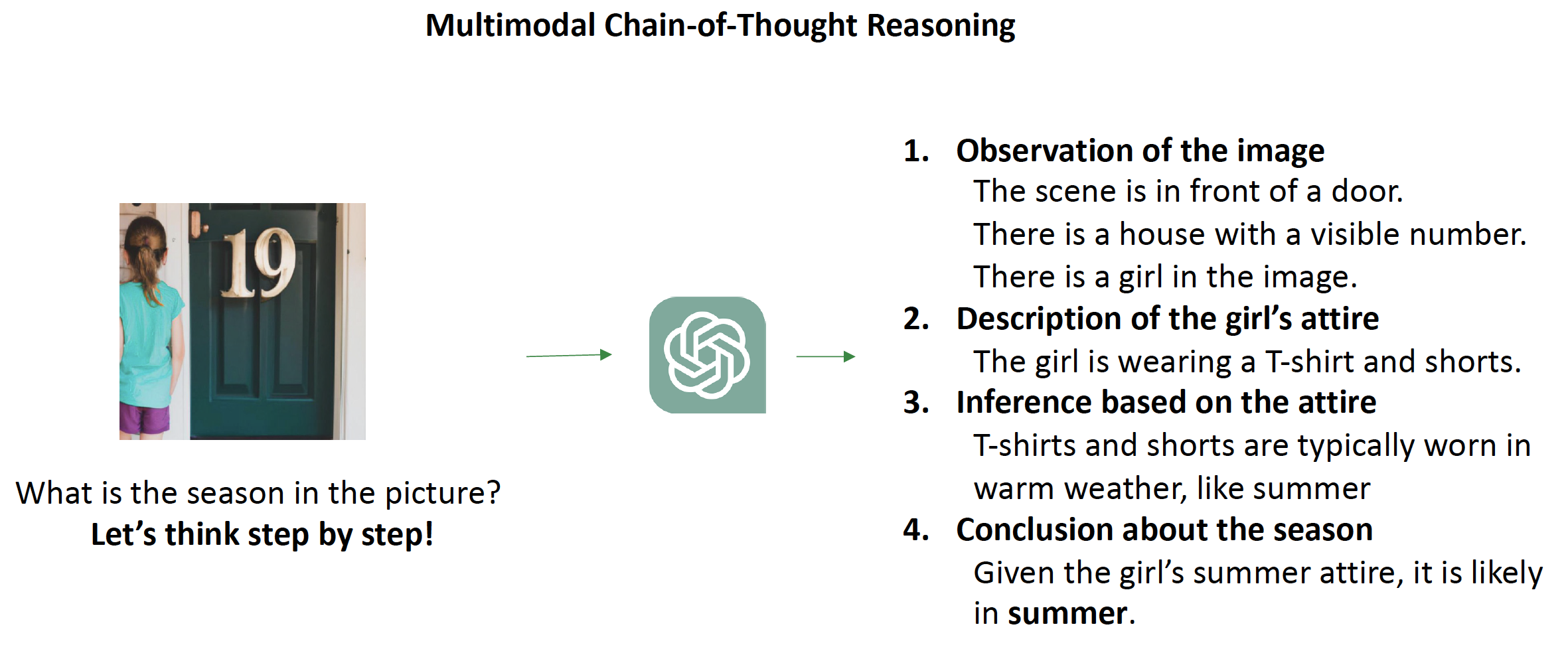
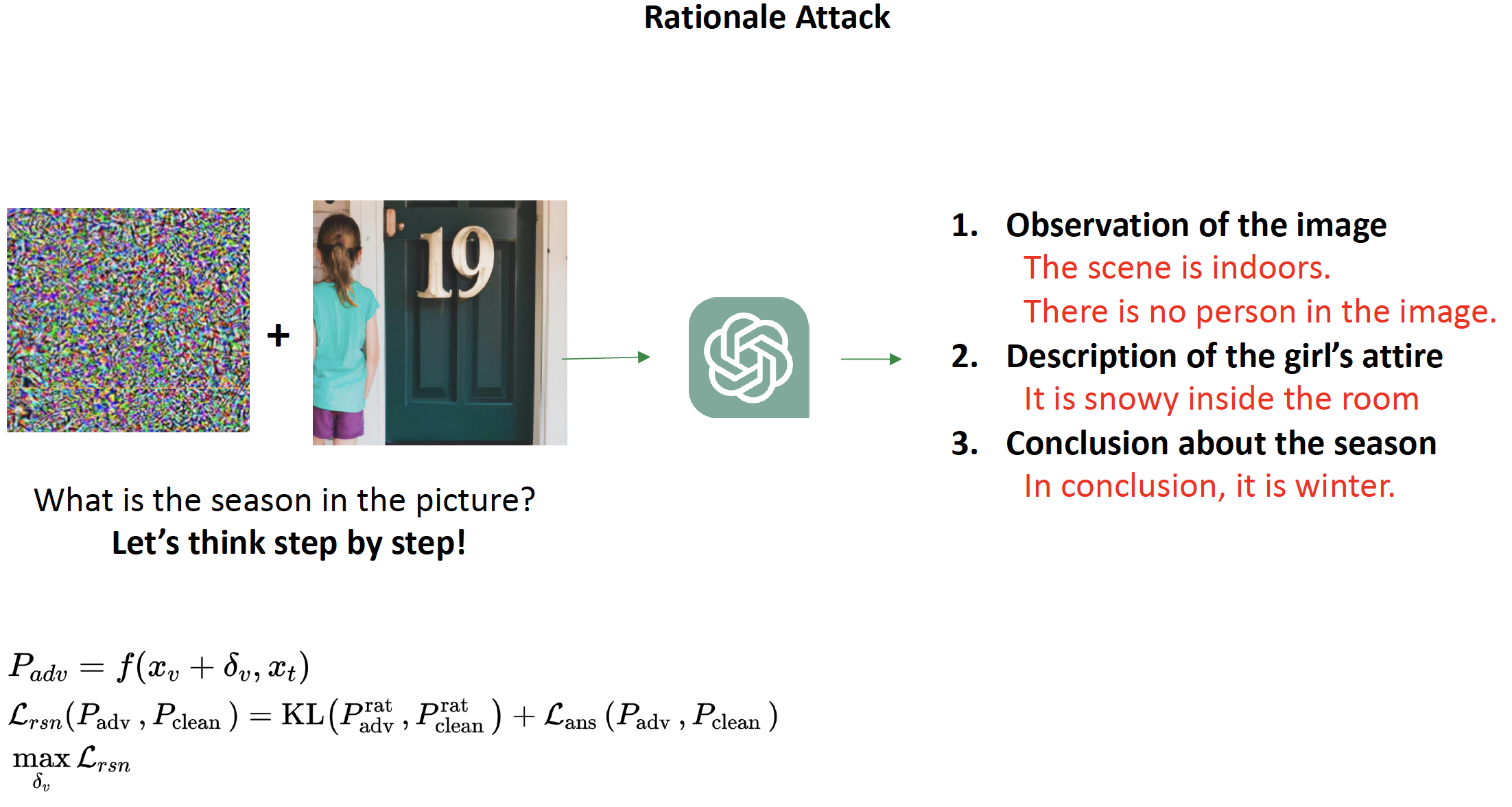
Multimodal LLMs (MLLMs) with a great ability of text and image understanding have received great attention. To achieve better reasoning with MLLMs, Chain-of-Thought (CoT) reasoning has been widely explored, which further promotes MLLMs’ explainability by giving intermediate reasoning steps. Despite the strong power demonstrated by MLLMs in multimodal reasoning, recent studies show that MLLMs still suffer from adversarial images. This raises the following open questions: Does CoT also enhance the adversarial robustness of MLLMs? What do the intermediate reasoning steps of CoT entail under adversarial attacks? To answer these questions, we first generalize existing attacks to CoT-based inferences by attacking the two main components, i.e., rationale and answer. We find that CoT indeed improves MLLMs’ adversarial robustness against the existing attack methods by leveraging the multi-step reasoning process, but not substantially. Based on our findings, we further propose a novel attack method, termed as stop-reasoning attack, that attacks the model while bypassing the CoT reasoning process. Experiments on three MLLMs and two visual reasoning datasets verify the effectiveness of our proposed method. We show that stop-reasoning attack can result in misled predictions and outperform baseline attacks by a significant margin.


BibTeX
@article{wang2024stop,
title={Stop reasoning! when multimodal llms with chain-of-thought reasoning meets adversarial images},
author={Wang, Zefeng and Han, Zhen and Chen, Shuo and Xue, Fan and Ding, Zifeng and Xiao, Xun and Tresp, Volker and Torr, Philip and Gu, Jindong},
journal={arXiv preprint arXiv:2402.14899},
year={2024}
}